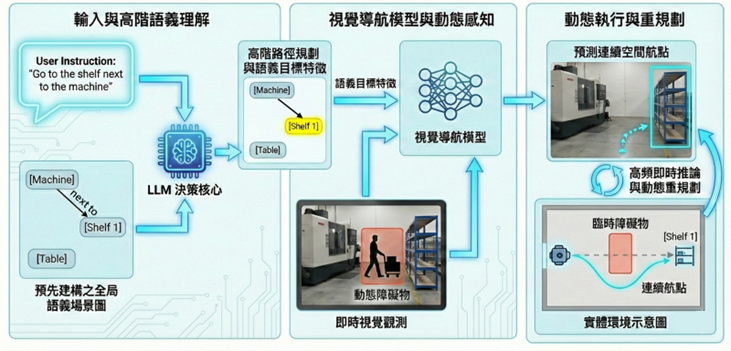
| 研究目標 在真實工業場域中,臨時障礙物與移動人員等動態變異,常使得預建的靜態地圖與即時場景產生落差,導致傳統導航系統的可靠性下降。此外,僅關注「無碰撞移動」的幾何導航邏輯,難以勝任需要深度理解任務指令的複雜需求。為此,本團隊致力於開發結合具身問答(Embodied Question Answering, EQA)架構之導航技術,旨在賦予機器人更高級的場景理解與自主探索策略。 本研究的目標是利用大型語言模型(LLM)作為決策核心,解析自然語言指令,並於語義場景圖中檢索目標以生成高階路徑規劃。在局部執行端,我們致力於導入視覺導航模型(Visual Navigation Model, VNM),將導航轉化為條件序列生成問題。透過整合多模態語義特徵與即時視覺觀測,模型能預測短時間內的連續空間航點,使機器人在無需先驗幾何地圖的狀況下,單純依賴視覺特徵鎖定目標並判斷可通行區域。 本研究最終期望透過模型的高頻即時推論與動態重規劃(Re-planning)機制,使機器人能靈活應對複雜場域中的動態干擾。這將實現從自然語言理解、空間語義檢索到安全避障控制的完整閉環,讓智慧機器人在變動不居的工業環境中,具備如人類般靈活且具備任務認知的移動能力。 |
||
|
||
圖1、基於大型語言模型之路徑規劃示意圖 |
||
|---|---|---|